
You should be freaking out about AI
It works and it keeps getting better at an insane pace

I interrupt my regularly scheduled social science content to briefly vent about the incredible pace of change that’s going on around us without most people even noticing or caring, which is mildly infuriating to me.
I could start this post, and I guess I am doing that right now, by wheeling out all the usual suspects. The scaling laws, for instance, which describe how AI model performance improves predictably with increases in compute, data, and model size - and which have held remarkably well over the past several years. The Stanford AI Index 2025 reports that training compute for frontier models continues to double roughly every five months, datasets every eight months, and power consumption annually. The inference cost for a system performing at GPT-3.5 level dropped over 280-fold between November 2022 and October 2024. And that was 2024! Who cares about 2024? In one sense, everything has already changed just since 2024.
Then there’s the infamous METR graph. A bit over a week ago, the latest evals (GPT 5.2) were added, and it looks like this. Performance is definitely hitting “a wall,” just not the kind of wall you’d think! It’s a vertical wall, not a horizontal ceiling. In other words, “Looks like we're going to need a taller sigmoid...” So, forget about exponential progress slowing down “any day now.”


Of course, in the meantime, we already got newer, better models (Opus 4.6 and Codex 5.3).
Yes, there are some issues with METR, but you can’t just wholly discount it. Or if you really do want to discount it, take a look at the Remote Labor Index (composed of many diverse freelancer tasks). As one of the top superforecasters Peter Wildeford notes, performance is doubling every ~4 month, meaning that (if trend continues), we get to virtually full RLI automation by late 2029.

So, I could cite the steady improvements on benchmark tests that were once considered AI-proof and which no one intuitively felt would fall just a few years ago. The progression has been from models that couldn’t reliably do basic arithmetic to ones that are now producing novel mathematical results and substantially assisting with (actually, more and more automating) scientific research.
I could quote Nobel Prize winners with literally 1mil+ citations, top computer scientists, and industry leaders (with the latter having strong incentives not to scare us) like Geoffrey Hinton, Yoshua Bengio, Ilya Sutskever, Demis Hassabis, Dario Amodei, and so on, who have all expressed serious concern about where this is heading and would like it if progress stopped immediately. Or I could point to what’s reportedly happening at places like the Institute for Advanced Study, where, according to one account from a closed meeting, leading physicists agreed that AI can now perform something like 90% of the intellectual work they do.
One of the world’s top coders Andrej Karpathy recently described how his workflow changed over just a couple of weeks in late 2025:
I rapidly went from about 80% manual+autocomplete coding and 20% agents to 80% agent coding and 20% edits+touchups. I really am mostly programming in English now.
I could walk you through the prediction markets. Metaculus forecasters, as of early 2026, average a 25% chance of generalized AI or AGI, which is as good as humans at most economically valuable tasks, by 2029 and 50% by 2033, down from a median estimate of 50 years just a few years ago (2020). The Manifold prediction market puts the probability of AGI before 2033 at roughly 50%. Samotsvety, a group of superforecasters with a strong track record, gave a 28% chance of AGI by 2030 in their old 2023 estimates.
I could note that even Gary Marcus, one of the most prominent skeptics of large language models, who has spent years cataloguing their failures and limitations, and who remains deeply critical of the hype surrounding current systems - even he thinks things are about to get serious really fast. As he put it, LLMs may not be AGI, but they are a “dress rehearsal” for it.
And I could say many, many more things along those lines. But I don’t want to bore you with what you probably already know.
You’re not using it, and you’re not thinking correctly, if you’re not astonished
What I do want to say is that you should be worried, in a healthy way, whatever that means. You’re probably not ignorant of the fact that big things are happening (unlike most “ordinary” people), but you might be severely underestimating the pace and extent of change that has already happened. You might also not be trying to extrapolate the current state (and, more importantly, the actual trajectory we’ve been on for the past 3 years), at least if you’re not freaking out. But you should be extrapolating it.
I admit to being somewhat doomer-pilled on AI (though, for what it’s worth, not on any other issue), which usually doesn’t go over well with people, so don’t over-index on that. Yes, I think there’s an uncomfortably high, though not exorbitantly high, probability of all this going very wrong in the medium term for humanity. But leave that aside. I might well be wrong about that.
What I’m less likely to be wrong about is that even just current LLM capabilities are ridiculously good, while most people are wholly oblivious to the fact. That’s such a strange in-between, limbo state of being for me. I’m just waiting for the moment when normal people finally start realizing how crazy what’s happening has been. But, okay, I can sort of understand normal people. However, for academics and researchers, being oblivious still in 2026 is totally baffling to me.
First, the fact that LLMs have gone from being almost wholly useless for writing, copy-editing, brainstorming, critiquing and reflection, data cleaning, coding, quantitative analysis, and visualization in Spring 2023 to (in my mind) being on the whole and with some prodding better than the median researcher in Winter 2025/26 is inexpressibly astonishing to me. Each year from 2023 on, I tried writing (for fun) a whole research paper (like the ones I usually write) solely off of simple LLM prompts. Until December 2025, I never really got that close. At first, even the general ideas LLMs had were sort of off. Then, the ideas got better, but they had too many problems with loading and cleaning the datasets. Then, when data handling got better, there was still the problem of hallucinated references. Also, visualizations were sometimes kinda wacky, and the analysis, although somewhat passable, were not that detailed, interesting or rigorous.
Slowly, especially over 2025, all that improved bit by bit; again, in my experimentation and judging by my perhaps my own flawed standards.
Then, with the very recent advances in models and especially Claude Code/Codex, I was at last able to create a full 25-page research paper from start to finish using only some fairly basic prompting. There were no hallucinated facts or references (on account of using the Deep Research function for the lit. review), the analyses were not groundbreaking but were totally what you’d expect in an average research journal, the writing was not AI slop (“It’s not X, it’s Y. … And you know what—that hits different. … The result? Shocking. … And here’s the thing.”) but standard academese, the visualizations were appropriate and attractive, and most importantly, I couldn’t find any errors in the analyses themselves or, of course, the interpretations of results when I redid everything manually myself. No formatting issues either.
When I put more effort into prompting and did a “day-long” back-and-forth with Codex 5.3 (extra high), where I have a whole pipeline with R, LaTeX, custom skills files, and so on, the final output was of course much better; something that could probably land in an average 1st quartile social-science journal. From my perspective as an academic researcher, that’s wild. (I put day-long in quotes because there was a lot of free time in between my prompts and the agent working. I just had to check in once in a while.)
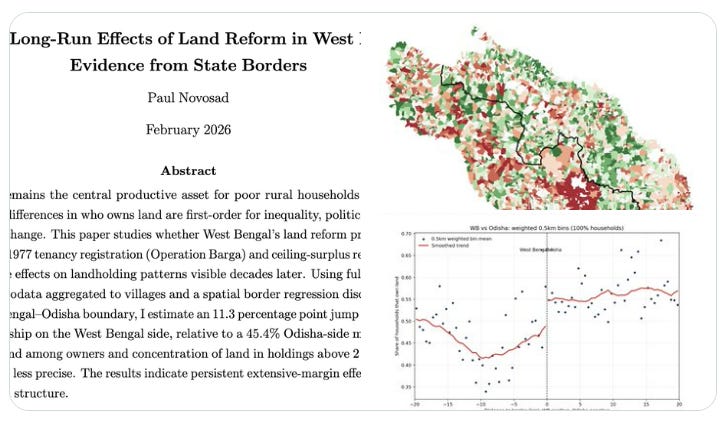
And obviously, I’m nothing special. Just yesterday, Paul Novosad did the same thing! Took him 2-3 hours. As he says:
I wrote a decent paper with AI.
It took me about 3 hours from start to finish, including an interactive choose-your-own-border-RD-adventure, it’s a what are we even doing here kind of day.
I kicked the tires pretty hard. The data are reasonable, the result is correct, the lit review is decent.
In another hour, we could have robustness, appendices, all the pieces of a good quality paper, and the question is legit.
I legit don't know how the journals are going to handle this. The cost barrier to doing and writing about new analytical work is going to zero.
I just question how the current system can continue to operate.
Is it “cheating” to build an entire journal article with AI? Surely not, if it's asking a good question and providing a good answer.
But if your living depends on publishing papers like these...
So what?
Okay, so it can write full academic papers of the quality that most researchers (barring the absolute elite) aspire to - so what? Well, first, “so whatting” AI whenever there’s an incredible advance that was previously, just a year or two ago, virtually unfathomable and the perceived impossibility of which was used to mock LLMs back then has become a crazy tactic at this point. Please, realize this and stop moving the goalposts. The progress has been insane.
Second, try not being a stochastic parrot and use just a bit of that allegedly uniquely human power of creativity and extrapolation. (At this point, I’m becoming more and more convinced it’s actually LLMs that are able to be creative and think outside the box, while most humans are just horrible at this. And I’m only half joking.) That is, do you really think what I said about AI progress in the scientific domain won’t/isn’t already spilling out to virtually everything else? I get that fully automating research papers isn’t the thing that gets normal, non-academic people all hot and steamy, but how can you think that, in (relatively short) time, this isn’t coming for every other task/job?
Third, I’m in the fortunate-unfortunate position where I really like my job. I like reading papers, writing stuff, thinking through problems, and doing (quantitative) analysis. Of course, I can still do all of that manually if I want in this or the future AI world, but I don’t think it’s actually that easy. For one, I’m not sure I’ll retain the same passion for reading, writing, and analyzing in a world where doing so manually is completely unnecessary and even a significant hindrance and a cost. Moreover, in a world where I (and everyone else) can get spoon-fed detailed information that I’d otherwise get through manual reading, and where problem-solving and analysis just come pouring out of the machine with a few button clicks and in three minutes, I’m not sure I’ll still intrinsically value the underlying process.
Even if I refuse to use AI for the supposed purposes of personal gratification that I get from reading and writing (manually), I’m not sure that’ll still seem worthwhile and enjoyable to me! Perhaps it still “should be” worthwhile and enjoyable, like hobbies are, but my introspection is telling me things are going to at least get much more complicated if not wholly broken down in this respect. And if I’m feeling this already today, just wait for 2029 or 2030. I can’t even imagine where we’ll be by then, if progress continues. And I don’t see any clear signs of it stopping right now.
My overall feeling currently was well expressed by an X rando the other day:
I like this interregnum where I can do things with AI that I think are interesting and worthwhile. But I worry that it’s going to be a short time before my added value is reduced dramatically.
Or as Noah Smith put it recently:
It occurs to me that this represents something momentous — the end of an economic age. My entire life has been lived within a well-known story arc — the relentless rise, in both wealth and status, of a broad social class of technical professionals. That rainbow may now be at an end. The economic changes — not just on careers, education, and the distribution of wealth, but on the entire way our cities and national economies are organized — could be profound.
Or Eric Levitz just yesterday:
[T]he bulls’ case has gotten stronger. Today’s AI systems are already powerful enough to transform many industries. And tomorrow’s will surely be even more capable. If celebrations of the singularity are premature, preparations for something like it are now overdue.
Check for yourself
If what I’m saying doesn’t resonate with you, do yourself a favor. First, check if you’ve been a regular and intense user of (paid!) frontier LLM models for the past 2 or 3 years. Also, check if you’ve spent at least a few hours with the latest AI agents, like Claude Code and ChatGPT Codex. If so and you’re not really worried or feeling a bit down, check whether you’ve actually been thinking about this stuff or just going through the motions. Really try hard and be honest. Now, if you’ve actually been explicitly thinking about it and didn’t engage in any goalpost-moving and weren’t dismissive of uncomfortable conclusions just because you can’t face them, then fine. Perhaps I’m thinking about it incorrectly or perhaps we’re just different people. That’s okay.
But if you haven’t been intensively using the technology or seriously thinking about issues surrounding it (and, obviously, worries about water and silly stuff like that don’t count), then you should consider changing your ways or simply not opining on what’s happening.
Some recent and accessible Substack resources you should read or listen to on these topics:
Addressing Objections to the Intelligence Explosion and Michael Huemer Is Wrong About AI Hype by Bentham's Bulldog.
Claude Code 17: The Zero Profit Condition Is Coming by scott cunningham
By the way, it seems pretty clear to me that Cunningham used one of the models heavily to write his post. When Scott Cunningham is using LLMs to write his Substack posts, I think we know where the future lies. :(
I agree with your vent when you're critiquing the "stochastic parrot" crowd; AI is clearly a big deal. I myself pay for Claude and use it almost daily. But I think you are overconfident in your projections of how rapid AI progress will be and how quickly jobs will be automated. "AI is a big deal" =/= "AI will replace all white collar work in 5 years". It's certainly possible that AI will replace most cognitive work in the near future, I wouldn't be shocked, but there's plenty of good reasons for skepticism too.
You talk about scaling laws, but we are running out of non-synthetic data to train models on. We have seen rapid progress in coding and math because it's easy to generate large amounts of synthetic data and verifiable problems, but it's not clear we will find ways to do this for other kinds of tasks. Compute can scale, but if training data ceases to scale then it's unclear if progress will continue at the same rate.
Claude Code is awesome and will require us to rethink how many white collar jobs function, but it's still far from replacing researchers or programmers. Look no further than the fact that Anthropic themselves have over 100 engineering job postings on their website. It will certainly accelerate and augment human engineers and researchers, but it seems unlikely a generalist could get Claude Code to create publishable academic papers at a high rate of reliability.
"But they keep getting better at a rapid rate". Again, though, we're running low on training data, and many of the recent improvements seem to be in introducing tooling and "harnesses" for the AIs rather than underlying model improvements. The gaps between where AI is now and a human researcher seem unlikely to be solved merely with tooling. It's things like high context knowledge, creativity, taste, continuous learning, episodic memory, more robust generalization, reliable intuitions about the physical world, and so on.
One last point I'll make is I feel like whenever progress in AI is made, people freak out and overestimate how powerful the AIs are, but over time as they use them more and more they see more of the flaws and limitations. It seems like we're at the beginning of another one of those cycles with coding agents.
Remember when GPT-4 first came out, and people were saying it would immediately replace countless jobs? That didn't happen because we realized it was more limited than we had realized at first. I remember similar things when Deep Research capabilities came out. At first, they seemed miraculous, but now they seem more like a tool that a researcher uses rather than a replacement. I've found that Deep Research tools have lots of limitations and they're just a supplement for me actually searching for and reading things myself. Don't get me wrong, incredibly useful, but not a replacement for humans. And I'm just an amateur researching things for fun.
My job is in science basically earth and ecosystem science with satellite and other data. Reading some of the recent stuff about how quickly agentic AI is advancing I thought, ok, let me try to just tell it a project and see if it can develop the code to do the analysis. How much input from me will it need?
The answer is, yes it can write code related to the project but with huge caveats that necessitate having an expert spending a lot of time on overseeing it.
So for example, it will generate a script for an analysis that I prompted it to. But then first issue, there’s a bug in the code and when I give it the error output, it latched on to one theory of what’s causing the error and went down a path rewriting everything according to this idea that ended up being wrong. Not only that but after correcting it, it still kept fixing future bugs according to that old theory even after being reminded several times that this was wrong. In the end it would have had a bunch of pointless processes in the code without me catching this.
Second, it chose technically correct datasets, but when I really looked at the data I realized, it’s not the right data to answer the question. It was data which was one processing level too high and which was processed using assumptions that would have essentially messed up the analysis. We needed a different dataset but without being able to look at the data visually the model wouldn’t have caught that.
Next, I had a factor that I would need to correct for or else the analysis would be pretty useless. The AI didn’t catch this on its own, so I had to suggest doing the correction. Ok, it accepts the need to do so, but of course the data used to correct it itself has some biases that that may mess up the analysis. So I ask the AI what are some approaches?
I’ll get specific here and say the factor we’re trying to correct for is the seasonal changes in leaf biomass in tropical forest. The AI suggests, well, since tropical forests don’t change their biomass much seasonally, we can just go without doing it.
I know that’s wrong. I tell it, no, go do research and tell me how much tropical forest canopy biomass varies seasonally. It comes back. Oh, canopy biomass varies by as much as 25% over seasons. The seasonal correction is ESSENTIAL to do. (The all caps was the model saying this). It wouldn’t have caught this without me knowing that its answers were incorrect. It took my guidance to go from “we can go without doing this because x”, to “it’s ESSENTIAL to do this”.
Continuing on, it got stuck into a loop of improperly aligning pixels, proposing one fix, the fix being wrong, proposing another fix, that fix being wrong, and all the time the interpretations of what’s wrong and the proposed solutions are getting more and more complicated. (A loop that LLMs seem quite prone to). Several times I had to tell it, no! Were getting too complicated. Simplify this down to the most basic solution. But even after saying this, it still likes to keeps elements of the failed approaches in the code which start to cause problems.
In the end my conclusion is, LLMs are good at doing basic and common things which are well represented in their training data. But they struggle when a task requires precise domain level knowledge which is not well represented in the training dataset. They also are prone to overconfidence in their interpretations, for example given a bug, and can get stuck in the cycle of rising complexity which they can really struggle to step back from or escape, sometimes even with guidance.
Some of this like the precise domain knowledge challenge may sound specific to my own obscure science problem. But I think most applications also rely on some level of quite specific domain knowledge that won’t necessarily be well represented in LLM training data, if at all.
So can it do my job while I go sip coffee? No. It needs an expert sitting there checking every step and every assumption.
In the end it might save some work for me (and it really has been amazing for me in other ways), but the need to check its work and assumptions and correct its misunderstandings for many cases end up taking just as long as having written the script myself would have been.